
土木论剑团队
『摘要』
本文讨论了变量抽样检验的基础原理。数学是对自然理解的抽象,从数理统计原理出发制订的变量抽样检验计划与所验收的对象无关,只要求变量服从正态分布。正态分布是这些变量之间的共同特性,这是抽象分析问题的一个重要实例。文中依据数学原理,分析了现行标准(GB/T50107)关键条文中各系数深刻的数理统计原理,并由此讨论了如何认识和使用标准的问题。
『关键词』抽样检验 数学模型 强度验收评定 抽象 混凝土强度
1、简介
混凝土强度的检验评定方法以GB/T50107(GBJ107)为代表,已在我国混凝土行业内使用了多年。它实质上是利用了统计质量控制这一大领域中的变量抽样验收(variable sampling plan)计划的基本原理,为混凝土生产方和使用方提供的混凝土质量验收计划中的一种总体(lot)验收方法。深入理解这一标准,必定为我们正确理解、使用标准,以及今后约定标准和调整标准提供坚实的理论基础。这是我们这篇博文要讨论的主要内容。
统计质量控制的基础是概率论与数量统计的基本思想和它们的主要结论,这方面的著作、教材以及课程讲义比比皆是,其内容也非常繁多,不可能在这一篇小小的博客文章中介绍,因此我们假定读者已充分理解和熟悉概率论和数量统计的基本思想和主要结论。另外,本文的目的也不是介绍用于质量控制的抽样检验,因此也假定读者充分了解了抽样检验的所有概念。
混凝土的强度验收评定是一种变量抽样(variable sample)的单边的验收计划,所针对的指标是其立方抗压强度。我们要验收检验的一批混凝土称为检验总体(lot),检验总体的一个重要指标是立方抗压强度,它是一个随机变量,服从正态概率分布。由于混凝土数量大,且要构成结构,因此不能采用全检验的方法验收,只能使用抽样检验的方法。
总体的被检验评定指标服从一定的概率分布。变量抽样计划要求针对总体,规定抽取一定数量的样本以及相应的限定值,当与指标相关的某一数量值大于规定的限定值时,则拒绝接收此总体的产品,反之则接收。当然,这是单边限定的情况,如果要双边限定,则要规定两个限定值,该数量值应该落在此限定值规定的范围之内。这种由样本数量和限定组成的一种抽样方案用于检验验收产品的某一项技术指标的方法我们称为一项抽样验收计划。
由于产品指标服从某种概率分布,因此从中所抽取的样本所测量的某一数据也会服从某种概率分布。如果规定样品合格率(p),在此抽样验收的情况下,接收此总体的概率为p'。在这种计划下,就存在两种风险,一种是总体合格,但抽样验收拒收,我们称为第一种风险,此时它的概率为\alpha,即拒收合格产品的概率为\alpha,此时的接收概率达到p'=1-\alpha。另外一种风险是接收不合格总体,我们专门用概率\beta表示此时的接收概率p'(即发生接收不合格产品错误的概率)。为了叙述方便,我们称拒收合格总体的错误为第一类错误,而接收不合格总体的错误为第二类错误。它们分别反映了生产者风险和接收风险。这就是抽样检验的数学模型。在下一节,我们把这一模型用于混凝土立方抗压强度的检验评定,去探究相关标准中的验收评定公式和相关系数的来历。
2、混凝土立方抗压强度的验收评定计划
现行国标中针对两种情况制订了抽样计划,一种是期望值\mu和方差\sigma已知的抽样检验评定计划;另外一种是\mu和\sigma均为未知时的抽样检验评定计划。这是两种针对不同生产过程的抽样检验计划,其样本数量(n)与限定值(k)完全不同,但是它们都有相同且深刻的统计学含义。明白它们的数学原理及其参数的含义,能帮助我们更充分理解生产过程控制中应该注意的事项。下面我们利用概率论和数理统计的基本原理分析上述模型抽样检验评定模型中的各参数的来历其及含义。
抽样计划除了样本数量和限定值外,还可以用验收曲线(operating curve,简称OC)表达。它的横轴是样品的不合格率,而纵轴则是在此不合格率的情况下的接收概率。
在下面的叙述中,我们都假定总体\mathcal{X}服从正态分布,即\mathcal{X}\sim\mathcal{N}(\mu, \sigma)。抽样检验评定计划的样本数量为n,其限定值为k。
2.1、已知方差
我们假定与指标相关的数值为Z=\frac{\overline{X}-L}{\sigma},当Z\geq k时接收该总体,而当Z< k时,拒绝接收该总体。其中L是生产控制值,在混凝土中,往往是所检验验收的强度等级值,比如C35强度等级值35MPa, 现行标准中常常用f_{cu0}表示。
根据概率的含义,我们有:
\mathcal{P}(\frac{\overline{X}-L}{\sigma}\geq k)
=\mathcal{P}(\frac{\overline{X}-\mu+\mu-L}{\sigma}\geq k)
=\mathcal{P}(\frac{\overline{X}-\mu+\mu-L}{\frac{\sigma}{\sqrt{n}}}\geq k\sqrt{n})
=\mathcal{P}(\frac{\overline{X}-\mu}{\frac{\sigma}{\sqrt{n}}}\geq\sqrt{n}(k-\frac{\mu-L}{\sigma}))\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(1)
我们知道,当\mathcal{X}\sim\mathcal{N}(\mu, \sigma),那么有n个样本的平均值\overline{\mathcal{X}}也是正态随机变量,并且\mathcal{\overline{X}}\sim\mathcal{N}(\mu, \frac{\sigma}{\sqrt{n}})。公式(1)中的\frac{\overline{X}-\mu}{\frac{\sigma}{\sqrt{n}}}为服从标准正态分布的变量,令Y=\frac{\overline{X}-\mu}{\frac{\sigma}{\sqrt{n}}},则有Y\sim\mathcal{N}(0, 1^2)。而\frac{L-\mu}{\sigma}也是服从标准正态分布的一个变量值,它就是总体分布在L处的值转换为了标准分布的值。
如果设:
z=\frac{\mu - L}{\sigma}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(2)
请注意,这里的z的值为\frac{\mu -L}{\sigma}而不是\frac{L-\mu}{\sigma}。如果通过累积概率查表,前者表示小于L的概率,后者表示大于L的概率。特别提请读者注意这里的细微差别。
我们把公式(1)写为
\mathcal{P}(Y\geq \sqrt{n}(k-z))=p'\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(3)
由抽样检验评定的模型我们知道,如果Y=y_1并且z=z_1时有y_1\geq k\sqrt{n}-z_1成立,我们接收这一总体,公式(3)表达了接收此总体的概率,设这个概率为1-\alpha,我们有:
\mathcal{P}(y_1\geq \sqrt{n}(k - z_1))=1-\alpha
它还可以写成:
\sqrt{n} ( k - z_1)=z_{(1-\alpha)}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(4)
公式(4)的意义在于当总体的变量大于L的概率为p_1(对应于\frac{\mu-L}{\sigma}\geq z_1)时,它的平均值\overline{X}会在服从\overline{X}\sim\mathcal{N}(\mu, \frac{\sigma}{\sqrt{n}})分布下,以1-\alpha的概率保证\frac{\overline{X}-L}{\sigma}\geq 0,此时可以接收此批总体。比如,当总体的强度值大于L的概率p_1= 0.95,则会以p'=1-\alpha=0.95的概率接收总体。
同样地,当变量Y = y_{2}时,对应于z = z_{2},我们可以得到如下公式(5):
\sqrt{n}(k-z_2)=z_{\beta}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(5)
公式(5)的意义在于,当总体变量减少,当Y=y_2(此时对应z=z_2,是一个很小的值),此时应该拒绝接收总体。但是在此时,总体变量仍然有p=p_2的概率大于L,因此\frac{\overline{X}-L}{\sigma}\ge 0的概率为\beta,仍然有可能接收此总体,接收此总体的错误概率为\beta。
如果我们规定p_1、p_1以及\alpha、\beta,那么由公式(4)和(5)就可以求解得到相应的样本数量n和限值k,也就是我们制订了抽样检验评定计划。
首先求解由公式(4)和(5)组成的方程组(需要利用了正态分布的对称性z_{1-\alpha}=-z_{\alpha}),我们得到:
n=[\frac{z_{\alpha}+z_{\beta}}{z_1-z_2}]^2\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(6)
k=z_1-\frac{z_{\alpha}}{\sqrt{n}}=z_2+\frac{z_{\beta}}{\sqrt{n}}=\frac{z_2z_{\alpha}+z_1z_{\beta}}{z_{\alpha}+z_{\beta}}\cdots\cdots\cdots\cdots\cdots\cdots\cdot\cdot(7)
公式(4)和公式(5)反映了两种总体在检验评定中的关系,它们之间的相互关系可见图1。图中右边的正态分布图表示接收总体时的总体及样本的分布。它的样本平均值大于L+k\sigma。左边的正态分布图表示拒收总体时的总体及样本分布,它的样本平均值小于L+k\sigma。

| 概率(%) | 标准值z | |
| p_1 | 95 | 1.645 |
| \alpha | 5 | 1.645 |
| p_2 | 50 | 0 |
| \beta | 10 | 1.28 |
假定我们分别设定,在p_1和p_2=0.50以及相应的\alpha和\beta=0.10(详细见表1),可由公式(6)、公式(7)计算得到n, k:
n=3.1\approx 3
k=0.72\approx 0.7
我们来看看标准GB50107-2010的条文5.1.2,它要求的是三组试件作为一组样本,其n=3,它的系数k=0.7,与我们的计算一致,它只是将n和k取整而已。所以该标准的条文规定:在以统计方法来做验收评定时,当总体的标准差已知,其抽样检验评定计划为:样本数量为n=3、限定值为k=0.7。
如果我们保持p_1=0.95和p_2=0.5不变,则根据标准的抽样检验计划规定的n和k,由公式(7)计算可得到z_{\beta}=1.21,此时有\beta=0.113。因此,GB20107-2010标准的5.2.1条文的抽样检验评定方案在总体以95%的概率大于规定值L时,它接收总体的概率也为95%,拒绝的概率为5%,当总体以50%的概率大规定值L时,它拒收总体的概率为87%,仍然有11.3%的概率会接收此总体。因此,此抽样检验评定计划发生第一类错误的概率为5%,而发生第二类错误的概率为11.3%。总体大于规定值的概率即总体的合格率。
可以推想,当总体的不合格率(1-p)从1%逐渐增高,则接收总体的概率也会逐渐减少。公式(4)可以看到,在规定了n和k值后,即抽样检验计划确定之后,可以确定总体的不合格率与接收率之间的关系。应用公式(4)计算OC曲线时,要注意p代表的是总体不合格率,1 - \alpha代表接收率,则z_{1- \alpha}代表的是接收率的标准值。由公式(4)可得:
z_{\alpha}=\sqrt{n}(k+z_{p})\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(8)
比如,合格率为p_1=0.95,则z_{1}=1.645, z_{\alpha}=1.64,即\alpha=0.5;而p_1=0.50,则z_{p_{2}}=0, z_{\beta}=1.21,即\alpha=0.11。这是我们设定的OC曲线上的两个点。特别是验收曲线上合格率为50%的点处的验收率即我们设定的客户风险概率,即第二类错误的概率。
图2显示了标准规定抽样检验评定计划下的OC曲线。该图中右侧的曲线是GB50107-2010中标准差已知条件下的抽样验收曲线。左侧的曲线是该标准在标准差未知时的验收曲线,它的抽样计划为n=15和k=1.10。
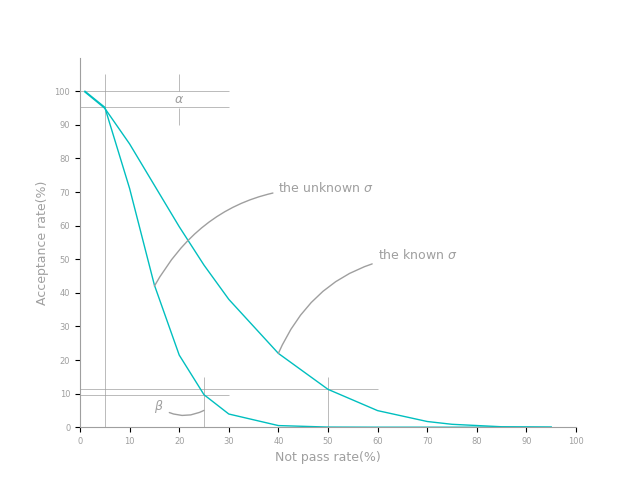
从上述我们看到,标准中的验收条件及相应参数都有严格的数学定义。以方差已知的情况为例,抽样检验评定计划的样本数量n和限定值k都有严格的统计学意义。如何确定这两个数值,可以通过数理统计原理在双方事先约定的风险条件下计算确定。一旦确定,生产方和客户各自都需要承担一定的风险。我们的现行标准为我们事先规定了双方的风险,即当总体合格率为95%的条件下,被拒收的概率为5%,接收的概率为95%;当总体合格率为50%时,拒收的概率高达88.3%,接收的概率为11.7%。当然,双方也可以依据公式(6)和公式(7)在事先约定的风险概率条件下设定样本数量和限定值。
通过上面的介绍,我们清楚地知道一个抽样检验评定验收计划的核心仍然就是总体均值的假设检验。有心的读者可以与均值假设检验比较。图2更清楚地显示了验收过程中合格率变化所带来的验收概率的变化。这是理解抽样验收评定的基础。也是我们下一步分析方差未知情况下基础。
2.2、方差和期望值未知
在分析方差未知时,我们需要先介绍某些样本分布的结论。
当\mathcal{X}\sim\mathcal{N}(\mu, \sigma^2)时,我们有:
\overline{X}\sim\mathcal{N}(\mu, \frac{\sigma^2}{n})
如果样本数量充分地大,比如n\geq 5,针对样本的标准差随机变量S有下述结论:
S\sim\mathcal{N}(a\sigma, \frac{b\sigma^2}{2\sqrt{n-1}})
其中:
a=\frac{\sqrt{\frac{2}{n-1}}\Gamma(\frac{n}{2})}{\Gamma(\frac{n-1}{2})}
b=\sqrt{2(n-1)(1-a)^2}
我们还知道随机变量\overline{X}和S是相互独立的。它们的联合概率分布可以写成p(x,y)=p(x)p(y)。两个相互独立的随机变量\mathcal{X}和\mathcal{Y}存在:
E(xy)=\sum_{y} y\sum_{x}(xp(x,y))
=\sum_{y}y\sum_{x}xp(x)p(y)
=\sum_{y}yp(y)\sum_{x}xp(x)
=\sum_{y}yp(y)E(x)
=E(x)E(y)
因此很容易证明:
E(\alpha X+\beta Y)=\alpha E(X)+\alpha E(Y)
当两个随机变量相互独立时,它们的方差有:
Var(\alpha X+\beta Y)=\alpha^2Var(X)+\beta^2Var(Y)
随着样本数量n的增加,随机变量S的分布参数中的系数a和b都趋近于1,我们假定a=b=1,则S的分布变成:
S\sim\mathcal{N}(\sigma, \frac{\sigma^2}{2(n-1)})
可以证明,如果两个随机变量都服从正态分布,那么它们的和也服从正态分布,由此我们可以知道\overline{X}-kS也服从正态分布,即:
\overline{X}-kS\sim\mathcal{N}(\mu-k\sigma, \sigma^2(\frac{1}{n}+\frac{k^2}{2(n-1)}))
为了简化书写, 我们设:
Y=\overline{X}-kS
\overline{Y}\sim\mathcal{N}(\mu-k\sigma, \sigma^2(\frac{1}{n}+\frac{k^2}{2(n-1)}))
同时我们还设:
\mu' = \mu-k\sigma
\sigma'^2 = \sigma^2(\frac{1}{n}+\frac{k^2}{2(n-1)})=\sigma A^{2}_{(n,k)}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots(9)
则的Y-L\geq 0概率可以写成:
\mathcal{P}(Y-L\geq 0)
=\mathcal{P}(\frac{Y-L}{\sigma'}\geq 0)
=\mathcal{P}(\frac{Y-\mu'+\mu'-L}{\sigma'}\geq 0)
=\mathcal{P}(\frac{Y-\mu'}{\sigma'}\geq\frac{-\mu'+L}{\sigma'})
=\mathcal{P}(\frac{Y-\mu'}{\sigma'}\geq\frac{-\mu+k\sigma+L}{\sigma'})
=\mathcal{P}(\frac{Y-\mu'}{\sigma'}\geq \frac{1}{A_{(n, k)}}(k - \frac{\mu-L}{\sigma}) )\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot\cdot(10)
在公式(10)中,\frac{Y-\mu'}{\sigma'}是随机变量的一个标准值,并且\frac{L-u}{\sigma}是X在L处的标准值。设:
z=\frac{ \mu-L}{\sigma}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot\cdot(11)
注意,公式(11)与公式(2)是一样的,表明下面所用的z均表示总体的不合格率所对应的标准值。
当随机变量X的均值为\mu_1时,它的合格率为p_1,由它的样本所组成的变量Y=y_1,此时y_1-L\geq 0,应该接收此总体,接收概率为\alpha,z_{(1-\alpha)}此时总体的合格率为p_1,此合格率的相应标准值为-z_1。因此,根据公式(9)我们可以得到:
\frac{1}{A_{(n,k)}}(k-z_1)=z_{(1-\alpha)}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(12)
当总体X的均值为\mu_2,其合格率为p_2,由它的样本所组成的变量Y=y_2,使得y_2-L\leq 0,此时应该拒收此总体,但仍然有接收概率\beta。我们可以得到:
\frac{1}{A_{(n,k)}}(k-z_2)=z_{\beta}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(13)由公式(12)和公式(13)可以得到(假定样本数量n很大,比如大于10,那么\frac{1}{n}\approx \frac{1}{(n-1)}):
k=\frac{z_2z_{\alpha}+z_1z_{\beta}}{z_{\alpha}+z_{\beta}}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(14)
n=\frac{z^2_{\alpha}}{(k-z_1)^2}(1+\frac{k^2}{2})\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(15)
n=\frac{z^2_{\beta}}{(k-z_2)^2}(1+\frac{k^2}{2})\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(16)
请注意,公式(14)与公式(7)是一样的,即限定值k的计算公式是一样的。
假如我们按表2约定:
| 概率(%) | 标准值z | |
| p_1 | 95 | 1.645 |
| \alpha | 5 | 1.645 |
| p_2 | 70 | 0.524 |
| \beta | 10 | 1.281 |
则利用公式(14)和公式(15)(或利用公式(14)和公式(16)可以计算得到:
k=1.015
n=13.86
我们再把公式(15)和公式(16)作一个变换:
z_1=k+z_{\alpha}\sqrt{\frac{1}{n}+\frac{k^2}{2n}}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(17)
z_2=k-z_{\beta}\sqrt{\frac{1}{n}+\frac{k^2}{2n}}\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdots\cdot(18)
按公式要求,在约定了概率后,每一个抽样计划的的样本数量和限值是成对出现的。如果样本数量n不同,则相应的k也不一样。当然,我们可以根据公式制定表格,从而确定不同的抽样计划,让它保持我们的约定要求。但是,从公式(17)和公式(18)可以看到,如果要保持z值不变,当n增加时,要适当地减少k值;而且,当n很大时,k值的变化也会非常小。因此GB50107-2010标准为了简化,按样本数量对k值作了分段处理。这就是该表中的限定值\lambda_1。在每一段中,样本数量n变动较小时,基本可以让总体不合格率(1-p)维持在30%左右,这时接收的概率为10%。随着样本数量增多,验收会更严格, 在总体不合格率更低时,即达到很低的接收概率\beta,详细见表3。
| k | 1.15 | 1.05 | 0.95 | |||
| n | 10 | 14 | 15 | 19 | 20 | 30 |
| p2(%) | 31.6 | 28.0 | 29.5 | 27.6 | 29.6 | 27.07 |
表3 抽样验收计划中,样本数量与限定值之间的关系
因此,在方差未知的情况下,我们的抽样检验评定计划的模型就是在给定的(n,k)情况下,与样本相关的随机变量\overline{X}-ks\geq L时,接收总体,而在\overline{X}-ks< L时,拒收总体。如果约定总体的接收与拒收合格率分别是p_1, p_2,则发生第一类错误和第二类错误的概率分别是\alpha, \beta。
同样地,我们也能利用公式(17)或公式(18)计算在给定计划的条件下,不同不合格率的验收概率,并做出相应的验收曲线。图2中左侧的曲线就是在给定n=15的k=1.10计划下的验收曲线。从曲线可以明显看出,此时曲线下降速度比标准差已知情况下的下降速度快了很多。因为约定更严格,标准差已知时,约定p_2=减少到50%时,其验收概率\beta才减少到10%,但标准差未知时,约定的p_2减少到70%时,\beta就已降低到了10%。因此可以说,标准差未知对生产方更严格,接收方的风险更低,而标准差已知的情况下,相对来说,接收方的风险更大。但是由于方差已知,表明生产过程控制更严格稳定,因此可以放宽对生产方的要求。
3、讨论
从前面的分析可以知道,制定验收评定计划与总体的期望值和方差没有关系,这些计划适合于所有的混凝土立方抗压总体,无论它们的期望值和方差是多少,甚至于可以不知道它们的具体数量。更进一步来说,它与所验收的对象没有关系,只要验收对象的验收指标(在混凝土工程中针对它的立方抗压强度而言)服从正态分布即可,因此,变量抽样验收是与验收对象无关的,这些讨论对于各种对象都适用。这就是一种抽象的过程,也是建立数学模型的过程。
从这个分析过程,我们认识到:
第一,从概率统计的观点出发,任何一个事件都有其发生的概率。我们对事物的认识总会有一定的局限,因此对影响过程的因素并未完全掌握,这表现在研究对象的指标上,会服从某种概率分布,指标总会有不合格的可能性。在此基础上,要从一个由众多数量组成的总体抽取有限数量的样本,并判断总体是否合格,也有可能产生第一类或第二类错误的可能。我们唯一能做的工作是如何控制产生这两类错误的概率。
第二,既然有产生第一类与第二类错误的可能,那么当某一次抽样检验评定时,发生拒收事件时,不可以就此认为总体中的所有产品都是不合格的,这需要进行甄别,验收评定计划并没有为这种甄别提供方法。从混凝土工程来说,可能需要对每一个已完成的构件进行单独检验,并利用概率统计原理对结构安全风险进行评估,在评估的基础上再决定每一个单独的构件是否可用。同时,从图2的验收曲线来看,在不合格率达到10%左右时,接受总体的可能性还是很高的,大多数时候仍然能接收该总体。所以,即使通过这类变量抽样验收,也不保证产品的合格率得到明确的保证。那么有人一定会问一个问题,即这个验收评定过程有何作用。我们认为,这个变量抽样验收评定过程是对质量问题的一个提醒。即当多次发生验收评定过程的拒收事件时,它在提醒我们,我们的生产控制过程有可能出了问题,某些可控制因素没有控制好。由于这个原理的抽象性,它并不能给我们提供线索,告诉我们究竟是那些因素的控制出现了问题。因此,这个验收评定过程并不能为我们质量管理提供线索。我们的生产过程仍然需要按照质量控制过程要求进行管理。
第三,从两个抽样计划来看,要保证验收合格,除了样本平均值要达到一定要求外,总体方差或标准差也应该尽可能地小,这样被接收的可能性会增大。而无论是方差或是标准差,都反映了总体指标的分散程度,如果过程控制好,比如,混凝土生产过程中用水量控制好,其强度的波动相对就小,则方差或标准差就小,即使其期望值或平均值不变,其产品的不合格率也会减少,因此被接受的可能性也会增大很多。所以,方差是反映过程控制的关键。而抽样检验评定利用了它的特点来反映过程的波动。
第四,现行标准为我们约定了抽样验收计划。但从这一数学原理出发,不同的风险约定会有不同的计划。我们仍然可以在双方协商约定的前提下,确定不同的风险,从而制定不同的计划,并由此确定在现实过程中是否真正拒收总体。这一点十分关键,只要遵守自然规律,在双方协商风险的基础上,是可以确定非标准的验收计划的。这也表明,单单了解标准条件的字面意义是不够的,理解标准背后的规律,并将规律用于生产过程控制更为关键。这也是现行标准从GBJ这种强制标准改为GB/T这样的推荐标准的根本原因。因为该标准并未完全列出所有计划供双方选择。

十分感谢您阅读我们网站的文章。如需转载原创文章,敬请注明文章出处及作者,并设置跳转到原文的链接!



